
操作系统:设计与实现
操作系统
Linux学习参考
Linux基础 — Linux Tools Quick Tutorial (linuxtools-rst.readthedocs.io)
硬件视角的操作系统
FFmpeg
FFmpeg 是一个开放源代码的自由软件,可以执行音频和视频多种格式的录影、转换、串流功能[6],包含了libavcodec——这是一个用于多个项目中音频和视频的解码器函式库,以及libavformat——一个音频与视频格式转换函式库。
“FFmpeg”这个单词中的“FF”指的是“Fast Forward(快速前进)”[7]。“FFmpeg”的项目负责人在一封回信中说:“Just for the record, the original meaning of “FF” in FFmpeg is “Fast Forward”…”
这个项目最初是由法国程序员法布里斯·贝拉(Fabrice Bellard)发起的,而现在是由迈克尔·尼德梅尔(Michael Niedermayer)在进行维护。许多FFmpeg的开发者同时也是MPlayer项目的成员,FFmpeg在MPlayer项目中是被设计为服务器版本进行开发。
- CPU reset之后我们的操作系统的代码是如何进行的?
- 先是
- qemu可以用gdb来进行调试
- gdb.init可以用来进行gdb的初始化
- makefile可以用来自动化测试
- 主引导扇区究竟是谁加载的?
Python 实现操作系统模型
操作系统是什么?
- 从应用程序角度来看,就是一条指令(system call)
- 从CPU reset开始,可以运行这样一个状态机
- 从上往下看,操作系统是一组对象,如进程、文件等
- 从下往上看,操作系统是一组状态机
- 那么有没有可能把状态机和状态画出来
讲概念的话,深入去问的话,其实是可以细节搞清楚的
- program counter是什么
- 操作系统里面的工具和概念
- strace是system all trace,追踪一个系统当中的系统调用
- 反正都是状态机
- 我们真正关心的概念
- 应用程序(高级语言状态机)
- 系统调用(操作系统API)
- 操作系统内部实现
- 没有人规定上面三者如何实现
- 通常的思路:真实的操作系统+QEMU/NEMU模拟器
- 我们的思路
- 应用程序 = 纯粹计算的Python代码+系统调用
- 操作系统 = Python 系统调用实现,有“假想”的I/O设备
- 我们真正关心的概念
操作系统玩具:API
- 四个“系统调用”API
- choose(xs):返回xs里的一个随机选项
- write(s):输出字符串s
- spawn(fn):创建一个可运行的状态机fn
- sched():随机切换到任意状态机执行
- train a b CD
- spawn pc会往前进一格
- 文件是操作系统的对象,文件描述符是指向操作系统中一个对象的指针。进程和线程是执行的状态机。
- 你在实现这个玩具的过程当中,就实现了执行的困难,所以我们玩具做的方法是我们当前的线程,蓝色的指针是不变的。
- 状态机的切换
- 蓝色的箭头是有点复杂的
- 我们的概念体系和我们的汇编语言是无情的执行指令的机器
- 概念体系和汇编语言都是一样的

- 操作系统是状态机的管理者
python语言机制:yield
yield是如何进行工作的
简单地讲,yield 的作用就是把一个函数变成一个 generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator,调用 fab(5) 不会执行 fab 函数,而是返回一个 iterable 对象!在 for 循环执行时,每次循环都会执行 fab 函数内部的代码,执行到 yield b 时,fab 函数就返回一个迭代值,下次迭代时,代码从 yield b 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到 yield。
也可以手动调用 fab(5) 的 next() 方法(因为 fab(5) 是一个 generator 对象,该对象具有 next() 方法),这样我们就可以更清楚地看到 fab 的执行流程:
generator是如何进行工作的
- 带有yield的函数在python中被称之为generator(生成器),何谓generator?
- numbers看成状态机,一种是纯粹的计算,一种是系统调用,将状态机的里面的信息暴露给外面
当一个函数其中有yield的时候,这个函数会变成generator,相当于一个状态机。纯粹的计算和系统调用,系统调用就是yield,相当于可以把内部的行为和结果告知外面。
yield,将当前状态的状态封存,然后将控制流交出去
控制流:控制流是指按一定的顺序排列程序元素来决定程序执行的顺序。[Visual BASIC](https://baike.baidu.com/item/Visual BASIC/287852?fromModule=lemma_inlink)、C和其他编程语言也继承了控制流,语句按照出现在程序中的顺序执行。[LabVIEW ](https://baike.baidu.com/item/LabVIEW /4165214?fromModule=lemma_inlink)使用顺序结构实现数据流框架中的控制流。顺序结构是一系列顺序执行的有序帧集合。顺序结构顺序执行帧0,然后是帧1、帧2,直到最后一个帧。只有最后一个帧执行完毕,数据才会离开结构。共有两种风格的顺序结构:单层顺序结构和叠层顺序结构,可以在Functions 选项卡的Programming>>Structures 子选项卡中找到。
如何实现?
- 我们会建立一个操作系统的Operating System的类,会建立一个Operating System.run
1 | #!/usr/bin/env python3 |
- sys_sche()将队列中的线程进行打乱,而蓝色的指针在这里始终指向队列的顶端,进而实现了shuffle随机选取到其他线程的操作
- return时候则直接将改线程remove出队列
C真实操作系统实现
1 |
|
- sys_write()调用printf
- sys_sched()使用了随机的睡眠(why?)
- sys_choose()返回其中random的元素
- sys_spawn()调用操作系统提供的接口
pthread_create - 希望能够在main函数开始之前进行一些代码,在main函数结束之后搞定一些代码
- 理解简化的东西和真实的东西之间的差异
建模操作系统

进程和线程
线程是共享内存的进程
- 有什么好处?
- 线程能够很快的读取其他线程的数据
- 但是存在权限的问题
- 有什么好处?
模型同时支持进程和线程
u盘拔掉,windows会给警告,告知不能这样做
- 再插上会告知要不要恢复数据
- U盘的闪存的速度是跟不上系统的写入的速度的,如果此时电脑发生了断电,或者U盘拔掉了,那么这时候的数据就不完全。
- 解释执行了状态机的运行,我们可以把状态机画出来
操作系统提供了什么api来创建一个进程
fork是进程状态机的完整的复制,不管多少的变量都会进行复制- 如果我们创建了十个线程
多处理器编程:从入门到放弃
Review
“操作系统玩具”给出了理解操作系统的新视角:操作系统时状态机的管理者,因为在sys_sched()之后操作系统拥有随机选择状态机执行的权利,因此也带来了并发性。操作系统是世界上最早的并发程序。
多处理器编程入门
1 | def Tprint(name): |
当进程可以共享状态的时候,
多线程共享内存并发
线程:共享内存的执行流
Ta和Tb真的共享内存吗?
- 如何证明这件事
函数内部的变量和全局变量在线程当中进行操作
如何证明线程具有独立堆栈(以及确定堆栈的范围)
- 输出混乱,应该如何处理?
建立一个无限递归的函数
setbuf(stdout,NULL)将输出缓冲区置为NULL- 当我们打印一个1并且如果crash掉了,那么这个1可能打印不出来
- 控制缓冲区,并且保证即使crash掉了也能得到相应的输出
更多的“好问题”和解决
- 创建线程使用的是哪个系统调用?
- 能不能用gdb调试?
- 基本原则:有需求,就能做到(RTFM)
放弃(1)原子性
1 | unsigned int balance = 100; |
当我们创建两个Alipay_withdraw并加以睡眠的时候(模拟线程的延迟),会出现极大的问题。
如果if条件被两个线程同时访问,那么就会进入其,并且同时扣除某个数字,最后超出int范围变成一个极大的数字。
单处理器多线程
- 线程在运行时可能被中断,切换到另一个线程执行
多处理器多线程
- 线程根本就是并行执行的
多处理器会带来指令的原子性被改变,放弃会带来指令和代码的原子性被颠覆
放弃(2)执行顺序
gcc -O2将这段代码自动转换为了addq一个数
编译器会将部分代码的运行顺序改变

放弃(3)处理器之间的可见性

CPI:cycle per instruction 每条指令的周期
x86会将我们的汇编代码分解为一种更小的代码
m1芯片能够分辨哪些变量是栈上的,从而减少一些load和store的指令数量
翻译为三条指令的时候就不原子了

Take-away Messages
在一个简化的模型中,多线程/多进程程序就是 “状态机的集合”,每一步选一个状态机执行一步。然而,真实的系统可能带来一些复杂性:
- 指令/代码执行原子性假设不再成立
- 程序的顺序执行假设不再成立
- 多处理器间内存访问无法即时可见
然而,人类本质上是物理世界 (宏观时间) 中的 “sequential creature”,因此我们在编程时,也 “只能” 习惯单线程的顺序/选择/循环结构,真实多处理器上的并发编程是非常具有挑战性的 “底层技术”,例如 Ad hoc synchronization 引发了很多系统软件中的 bugs。因此,我们需要并发控制技术 (之后的课程涉及),使得程序能在不共享内存的时候并行执行,并且在需要共享内存时的行为能够 “容易理解”。
并发控制:基础(Perterson算法、模型检验、原子操作)
四线程例子
如果有多个线程,每个线程都有两个操作,read和write。
每个线程都有本地的读写内存的记录。
如果每一个人都有对世界的观测,如果想将其合并为一个全局事件,那么这是一个np-complete问题
NP完全或NP完备 (NP-Complete,缩写为NP-C或NPC),是计算复杂度理论中,决定性问题的等级之一。NP完备是NP与NP困难问题的交集,是NP中最难的决定性问题,所有NP问题都可以在多项式时间内被归约(reduce to)为NP完全问题。倘若任何NP完全问题得到多项式时间内的解法,则该解法就可应用在所有NP问题上,亦可证明NP问题等于P问题,然而目前为止并未发现任何能在多项式时间内解决NP完全问题的方法。
手段:“回退到”顺序执行
- 标记若干块代码,使得这些代码一定能按某种顺序执行
- 例如,我们可以安全地在块里记录执行的顺序
回退到顺序执行:互斥
stop the world是可能的
- java有
stop the world GC - 单个处理器可以关闭中断
- 多个处理器也可以发送核间中断
直观的想法是同学能够有一个房间,房间里有一把锁,同学会怎么协调这两把锁?
错误的实现
1 | int locked = UNLOCK; |
更严肃的尝试:确定假设、设计算法
- val = atomic_load(ptr)
- 看一眼某个地方的字条(只能看到瞬间的字)
- 刚看完就可能被改掉
- atomic_store(ptr, val)
- 对应往某个地方“贴一张纸条”
- 贴完一瞬间就有可能被别人覆盖
Peterson算法
正确性不明的奇怪尝试(Peterson算法)
- 上厕所之前先把旗子举起来,并且向门上贴对方名字的字条,如果对方举着旗子,并且厕所门上名字是对方,就必须等待。
- 出厕所时,放下自己的旗子。
如果你的室友根本不在宿舍?
- 那么对方旗子肯定不会举起,可以直接进
如果同时两个旗子举起
- 那么先到的人的名字会被后来的人进行覆盖,手快有,手慢无
模型、模型检验与现实
Model Checker
- python的每一步的状态机的可能性就可以画出来,每一个要求就是互斥,
Peterson问题假设
- 如果结束后把门上的字条撕掉,算法还正确吗?
- 放下旗子之前撕
- 放下旗子之后撕
- 如果先贴标签再举旗,算法还正确吗?
- 我们有两个“查看”的操作
- 看对方的旗有没有举起来
- 看门上的贴纸是不是自己
- 这两个操作的顺序影响算法的正确性吗?
- 是否存在“两个人谁都无法进入临界区”(liveness)、“对某一方不公平”(fairness)等行为?
- 都转换为图(状态空间)上的遍历问题了!
从模型回到现实……
- 想要正确实现peterson算法,那么load和store的原子性编译器是做不到的,一定需要处理器的编译器的合作。
__sync_synchronize指令在x86平台上可以被翻译为mfence这类指令- 原子的load和store
486系统如何实现多处理器之间的原子的sum++呢
- 使用
lock前缀
lock前缀会更改什么行为
- 右边的部分是CPU的引脚,然后,在其中有一根线是LOCK#,应该是在往外实现送出去的时候。有
lock前缀的时候,LOCK#信号就会拉低,那么这个CPU就持有了内存的独占访问权,相当于一个总线锁,这个性质在80386的时候就被引入了,一直引入到了今天。

并发控制:互斥(问题定义与假设、自旋锁、互斥锁)
peterson的读和写
- 共享变量读到临时变量里
- 多处理器系统上面去运行这个系统
回顾的并发编程
- 不想纠结这些细节,直观、简单、粗暴的解决方法
原子指令
acquire得到之前所有的原子指令的信息release可以让过去所有的信息都对未来可见- 配对起来就是锁的释放和获取
atomic会比通常的指令更慢一些
atomic exchange实现
1 | int xchg(int volatile *ptr, int newval) { |
%0和%1代表什么?
- 后面描述的output和input
%rdi是x86的第一个参数,所以是将第一个参数的值放到1中,将a当中的计算器放到0中memoryclobber相当于一个compiler BARRIER- 上面的一小段代码能够保证我们的假设
实现互斥:做题家 v.s. 科学家
1 | void lock(lock_t *lk); |
科学家:考虑更多更根本的问题
- 我们可以设计出怎样的原子指令
- 它们的表达能力如何?
- 计算机硬件可以提供比“一次load/store”更强的原子性吗
- 如果硬件很困难,软件/编译器可以吗?
自旋锁
每个人都有一张卡,但只有一张红卡
1 | int table = YES; |
如果你的锁在return之前线程crash掉了,那应该怎么办?
- 借助cpp
RAII机制,resource acquisition is initialization,通过实现一个类来进行锁的保管 - resource的acquire和release
实现互斥:自旋锁
- 包含一个原子指令
- 包含一个compiler barrier
“Compiler barrier”(编译器屏障)是一个编程概念,用于指导编译器在生成机器代码时如何处理优化。编译器在优化代码时会重新排列指令顺序,以提高效率和性能。然而,在多线程或底层硬件交互的场景中,指令的顺序可能至关重要。在这些情况下,编译器屏障用来告诉编译器不要改变屏障两边的指令顺序。
在多线程编程中,编译器屏障的使用尤为重要,因为线程间的操作顺序对程序的正确性可能至关重要。例如,一个线程可能需要在另一个线程修改某个变量之后才能安全地读取该变量。如果编译器改变了这些操作的顺序,可能会导致竞争条件和其他并发错误。
编译器屏障通常用于以下情况:
- 防止编译器重排:确保编译器在生成汇编代码时保持源代码中指令的特定顺序。
- 内存可见性:在多处理器系统中,编译器屏障还可以确保内存操作的顺序,这对于正确同步共享数据至关重要。
需要注意的是,编译器屏障只防止编译器优化带来的指令重排序,它并不防止CPU在执行时对指令进行乱序执行。为了控制CPU层面的指令重排,需要使用另一种机制,称为“内存屏障”或“内存栅栏”(Memory Barrier)。
编译器屏障是系统编程和多线程编程中一个高级且重要的概念,它涉及到编译器设计、计算机架构和操作系统的底层工作方式。在使用时需要特别小心,因为不正确的使用可能导致难以发现和修复的并发错误。
自旋锁的方法很浪费?
- 某一个线程一直在做交换
- 有比较严重的性能问题
自旋锁的缺陷
- 处理进入临界区的线程,其他处理器上的线程都在空转
- 争抢锁的处理器越多,利用率越低
- 4个CPU运行4个sum-spinlock和1个OBS
- 任意时刻都只有一个sum-atomic在有效计算
- 均分CPU,OBS就分不到100%的CPU了
- 4个CPU运行4个sum-spinlock和1个OBS
- 如果线程比处理器的数量更多?
- 如果一个线程在拥有红卡的时候进行了线程切换,那么会出现百分百的资源浪费
冯诺依曼计算机结构
- 消息传递是一个问题,带来效率的降低
- 共享变量的LOCK和最终的变量SUM是在各个处理器之间传递的
我们希望能把线程让给其他资源用
实现线程+长临界区的互斥
- syscall
- 把锁的实现放到操作系统就可以
syscall(SYSCALL_lock, &lk);- 试图获得lk,如果失败,就切换到其他线程
syscall(SYSCALL_unlock, &lk);- 释放lk,如果有等待锁的线程就唤醒
- 临界区,spinlock换为mutex ,这部分CPU是不会浪费的
调试理论与实践
ssh -vvv www.baidu.com可以打印一些log信息
#include <stdio.h>在编译的时候会在一些路径之下去找这个库文件
GDB:入门
有python的binding,可以用python来drive这些东西
printf里面到底发生了什么?
record full在每一个状态机之间的diff都会进行记录
遗留部分内容
- 只要临界区交换是原子的,就没有问题
- 程序如果想要获得锁,就请求系统调用,操作系统如果发现这个线程没有办法得到锁的时候,就不调用这个线程,这样线程就不会有CPU浪费了。
Futex: Fast Userspace muTexes
set scheduler-locking on有一个线程的时候遇到了break point,那么如果其他线程仍然在跑,在做sum++,这个命令的含义就是在处理一个线程的时候,会停止其他的线程。
GDB简要命令
| 命令名称 | 命令缩写 | 命令说明 |
|---|---|---|
| run | r | 运行一个待调试的程序 |
| continue | c | 让暂停的程序继续运行 |
| next | n | 运行到下一行 |
| step | s | 单步执行,遇到函数会进入 |
| until | u | 运行到指定行停下来 |
| finish | fi | 结束当前调用函数,回到上一层调用函数处 |
| return | return | 结束当前调用函数并返回指定值,到上一层函数调用处 |
| jump | j | 将当前程序执行流跳转到指定行或地址 |
| p | 打印变量或寄存器值 | |
| backtrace | bt | 查看当前线程的调用堆栈 |
| frame | f | 切换到当前调用线程的指定堆栈 |
| thread | thread | 切换到指定线程 |
| break | b | 添加断点 |
| tbreak | tb | 添加临时断点 |
| delete | d | 删除断点 |
| enable | enable | 启用某个断点 |
| disable | disable | 禁用某个断点 |
| watch | watch | 监视某一个变量或内存地址的值是否发生变化 |
| list | l | 显示源码 |
| info | i | 查看断点 / 线程等信息 |
| ptype | ptype | 查看变量类型 |
| disassemble | dis | 查看汇编代码 |
| set args | set args | 设置程序启动命令行参数 |
| show args | show args | 查看设置的命令行参数 |
断言的意义
- 把代码中隐藏的specification写出来
- Fault - Error(靠测试)
- Error - Failure(靠断言)
- Error暴露的越晚,越难调试
- 追溯导致
assert failure的变量值(slice)通常可以快速定位到bug
并发控制:同步(1)
同步(Synchronization)
两个或两个以上随时间变化的量在变化过程中保持一定的相对关系
同步电路(一个时钟控制所有触发器)
并发程序很难完成生产者-消费者问题
打成同步的条件是代码写出来的
18行的时候,有的线程的条件可以被唤醒,从而正常实现生产者与消费者
同步问题:分析
线程join
Tmain同步条件:nexit == TTmain打成同步:最后一个线程退出 nexit++
生产者/消费者问题
Tproduce同步条件:CAN_PRODUCE(count<n)Tproduce达成同步:Tconsume count–Tconsume同步条件:CAN_CONSUME(count>0)Tconsume达成同步:Tconsume count++
条件变量:理想与实现之间的这种
一把互斥锁 + 一个“条件变量” + 手工唤醒
- wait(cv, mutex)
- 调用时必须保证已经获得mutex
- wait释放mutex、进入睡眠状态
- 被唤醒后需要重新执行lock(mutex)
- signal/notify(cv)
- 随机私信一个等待者
- 如果有线程正在等待cv,则唤醒其中一个线程
- broadcast/notifyAll(cv)
- 叫醒所有人
- 唤醒全部正在等待cv的线程
1 | wait until(cond) with (mutex){ |
条件变量:万能并行计算框架(M2)
三种线程
- Ta若干:死循环打印<
- Tb若干:死循环打印>
- Tc若干:死循环打印_
任务
- 对这些线程进行同步,使得屏幕打印出<><_和><>_的组合
解答
1 |
|
现代高性能处理器体系结构,会在RAW类似指令时进行拓扑排序,将部分指令进行简化。
同步:信号量与哲♂学家吃饭问题 (信号量的正确打开方式)
P和V操作来自于semaphere,P对应于wait
wait_until
条件变量比较low level
信号量是P成功一定会导致count--,V成功一定会导致count++
- P - prolaag (try + decrease & down & wait & acquire )
- 如果拿到了,离开
- 如果没拿到,等待
- V - verhoog (increase & up & post & signal & release)
- 如果有人在等球,他就可以拿走刚放进去的球了
- 放球 - 拿球的过程实现了同步
- 扩展的互斥锁
信号量:实现优雅的生产者-消费者
信号量设计的重点
- 考虑“球/手环”,
- 信号量这样的机制到底适合干什么,不适合干什么
信号量的两种典型应用
- 实现一次临时的
happens-before- 初始:s = 0
- A;V(s)
- P(s);B
- 假设s只被使用一次,保证
A happens-before B
- 假设s只被使用一次,保证
- 实现计数型的同步
- 初始:done = 0
- Tworker:V(done)
- Tmain:P(done) x T
对应了两种线程join的方法
如果在一个条件变量上broadcast然后丢掉了,信号量如果自带计数器,自带球,那么就会实现临时
线程库的join
- 可以分别用这两种方式实现线程的
join - 如果第一种方式
- T1结束的时候可以V(t1)
- T2结束的时候可以V(t2)
- 如果第二种方式(一个信号量)
- 两个线程执行完的时间
- 对每一次线程结束都会拿到一个球
- 马上信号量的真正的作用就来了
- 信号量可以用来实现任何计算图
实现计算图
对于任何计算图
- 为每个节点分配一个线程
- 对每条入边执行P(wait)操作
- 完成计算任务
- 对每条出边执行V(post/signal)操作
- 每条边恰好P一次、V一次
- PLCS直接解决
- 动态生成的计算图
- 实现信号量的“小鱼”
- 条件变量能把所有人都唤醒
使用信号量实现条件变量
- 不能带着锁睡眠 (NewBing 犯的错误)
- 也不能先释放锁
P(mutex); nwait++; V(mutex);- 此时 signal/broadcast 发生,唤醒了后 wait 的线程
P(sleep);
- (我们稍后介绍解决这种矛盾的方法)
哲学家吃饭问题
经典同步问题:哲学家(线程)
- 吃饭需要同时得到左手和右手的叉子
- 当叉子被其他人占用的时候,必须等待,如何完成同步
只允许四个人进桌吃饭或者奇偶分离
反思:分布与集中
能不能有一个集中的“总控”,而非“各自协调”
- 在可靠的消息机制上实现任务分派
- Leader串行处理所有请求(例如:条件变量服务)
- 如果能够收集信息,集中处理集中调度
管叉子的人是性能瓶颈吗?
- 一大桌人吃饭,每个人都叫服务员的感觉
抛开workload谈优化就是耍流氓
- 吃饭的时间通常远远大于请求服务员的时间
- 如果一个manager搞不定,可以分多个(fast/slow path)
- 把系统设计好,集中管理可以不是瓶颈:The Google File System (SOSP’03) 开启大数据时代
- 拉开了大数据的序幕
- 在八十年代的时候,发现存储设备每隔一段时间的容量和速度就会翻多少倍
高性能计算中的并行编程
高性能计算
- MPI - “a specification for the developers and users of message passing libraries”, OpenMP - “multi-platform shared-memory parallel programming in C/C++ and Fortran”
- Parallel and Distributed Computation: Numerical Methods
1 |
|
数据中心
分布式系统的问题,消息可能会是乱序
- 拉黑
- post朋友圈
可能会出现在拉黑的事件到达某一个服务器的时候,那么服务器之间还没有互相同步,此时存在延迟,如果发生了网络的中断或者post已经完成,那么就出现了消息的乱序。
如何实现高可靠、低延迟的多副本分布式存储和计算系统?
- 在服务海量地理分布请求的前提下,三者不可兼得:
- 数据要保持一致(consistency)
- 服务时刻保持可用(Availability)
- 容忍机器离线(Partition tolerance)
- 容错是不可能缺少的
- 刚刚兴起的时候
数据中心程序上的单机程序
事件驱动+高并发:系统调用密集且延迟不确定
- 网络数据读写
- 持久存储读写
- 单机程序目标:尽可能多地服务并行的请求
- QPS:吞吐量
- Tail latency:一个请求满了,其他请求不能慢
- 假设有数千/数万个请求同时达到服务器…
- 线程能够实现并行处理
- 但远多于处理器数量的线程导致性能问题
- 切换开销
- 维护开销
Goroutine
- 概念上是线程,实际上是协程
- 每个CPU上有一个Go Worker,自由调度goroutinues
- 执行到
blocking API时(例如sleep, read)- Go Worker偷偷改成non-blocking的版本
- 成功 - 立即继续执行
- 失败 - 立即yield到另一个需要CPU的goroutine
- Go Worker偷偷改成non-blocking的版本

Go语言中的同步
Do not communicate by sharing memory; instead share memory by communicating -- Effective Go
共享内存 = 万恶之源
- 信号量/条件变量:实现了同步,但没有实现“通信”
- 数据传递完全靠人工
UNIX时代就有一个实现并行的机制了
- cat * .txt | wc -l
- 管道是一个天然的生产者消费者
- 为什么不用“管道”实现协程/线程之间的同步+通信呢?
- Channels in Go
分布式机器学习
既计算密集,又数据密集
计算图如何需要并行化?
- 切分
- 可以把模型的一部分分到一台机器上
如果想要算代码,那么只需要一条指令,
Single Instruction, Multiple Threads
- 一个PC,控制32个执行流同时执行
- 逻辑线程可以更多
- 执行流有独立的寄存器
- x, y, z三个寄存器用于标记“线程号”,决定线程执行时的动作
用户身边的并发程序
web异步编程
web 2.0时代
- “Users were encouraged to provide content, rather than just viewing it”

真实世界的并发Bug
初学者到不是初学者遇到的最大障碍
从此以后再也不需要程序员了
并发程序到底对不对,有没有bug在里面,有效的诊断它是一个相对而言的经验,展示一些真实世界里的并发bug
伤人性命的并发Bug
“拿起”的物品会变成“捡起”的物品
- 视频
- 似乎是共享状态引起的
死锁
AA-Deadlock
1 | lock(&lk); |
当处于操作系统中时,会中断跳出现有的范围,如果此时再去LOCK访问这把锁的时候,那么就会产生AA型的死锁
ABBA-Deadlock
1 | void Tphilosopher(){ |
System deadlocks (1971):死锁产生的四个必要条件
- 用 “资源” 来描述
- 状态机视角:就是 “当前状态下持有的锁 (校园卡/球)”
- Mutual-exclusion - 一张校园卡只能被一个人拥有
- Wait-for - 一个人等其他校园卡时,不会释放已有的校园卡
- No-preemption - 不能抢夺他人的校园卡
- Circular-chain - 形成校园卡的循环等待关系
四个条件 “缺一不可”
- 打破任何一个即可避免死锁
- 在程序逻辑正确的前提下 “打破” 根本没那么容易……
数据竞争
不同的线程同时访问同一内存,且至少有一个是写
- 两个内存访问在“赛跑”,“跑赢”的操作先执行
- 例子:共享内存上实现的Peterson算法
Weak memory model
允许不同观测者看到不同结果
C++规定
- 每一个都是原子的操作
- 由锁建立了数据间的依赖关系
原子性和顺序逆反
并发编程的本质
- 程序分成若干“块”,每一块看起来都没被打断(原子)
- 具有逻辑先后的“块”被正确同步
- 例子:produce - (happens-before) - consume
并发控制的机制完全是“后果自负”的
- 互斥锁(lock/unlock)实现原子性
- 忘记上锁 – 原子性违反
- 条件变量/信号量实现先后顺序同步
- 忘记同步 – 顺序违反
原子性违反(AV)
顺序违反(OV)
concurrent use after free
如果已经有一块内存地址,一个指针已经被free了,那么所有对这段内存地址的操作都是ub,全都是不被定义的。
并发Bug和应对(防御性编程和运行式检查)
在任何时候总会有最靠右的一把锁
页面单位来分配的时候,在分配页面时会出现一把锁,每一个页面都有一把锁,那么怎么样锁排序呢?
有没有办法让程序员强制性的
Bug的本质和防御型编程
回顾:调试理论
一个递增数组检查一个二分查找
- “防御型编程”
- 任何可能不对的情况都检查一遍
防御型编程和给我们的启发
自助运行时检查
动态程序分析
- ABBA型死锁
- 数据竞争
- 带符号整数溢出
- Use after free
- ……
动态程序分析:状态机执行历史的一个函数
- 付出程序执行变慢的代价
- 找到更多bugs
死锁:通过lockdep进行检查
数据竞争检查
ThreadSanitizer:运行时的数据竞争检查
并发程序的执行trace
gcc tSanitizer=thread ***.c & ./&&&.out
- 内存读写指令(load/store)
- 同步函数实现
编译器知道每一次内存访问,所以也可以打印出每一个内存访问的信息
所有的线程会有一把自己的LOCK
Buffer Overrun检查
Canary的例子:保护栈空间
将栈的顶部和底部都覆盖一些特殊的值,如果任何数据出现了更改,那么这些代码出现了一些问题。
烫烫烫、屯屯屯
未初始化的栈和堆是这个值
gb2312是老的字库,通过解码为这个版本会出现烫烫烫
低配版AddressSanitizer(L1)
在alloc之前记得检查对应block的位是不是已经被置为1,表示已经被分配。
多处理器和中断(50行实现操作系统内核)
计算机从一个reset状态开始的,确定了pc的值,确定了其他的一些条件。
lab1中存在mp_init的api,使得虚拟机从一个单CPU的处理器编程多CPU共享一个内存的处理器。
中断机制
定义
中断(英语:Interrupt),又称插断,在计算机科学中是指处理器接收到来自硬件或软件的信号,提示发生了某个事件,应予以注意,这种情况就称为中断。
通常,在接收到来自外围硬件(相对于中央处理器和内存)的异步信号,或来自软件的同步信号之后,处理器将会进行相应的硬件/软件处理。发出这样的信号称为进行中断请求(interrupt request,IRQ)。硬件中断导致处理器通过一个执行信息切换(context switch)来保存执行状态(以程序计数器和程序状态字等寄存器信息为主);软件中断则通常作为CPU指令集中的一个指令,以可编程的方式直接指示这种执行信息切换,并将处理导向一段中断处理代码。中断在计算机多任务处理,尤其是即时系统中尤为有用。这样的系统,包括运行于其上的操作系统,也称“中断驱动”(interrupt-driven)。
理解中断
硬件上的“中断”
- IRQ:边缘触发,低电平有效
- 实际处理器不是无情地执行指令
- 是有情地响应外部的打断
处理器的中断行为
响应
eflags的flag的IF如果是1,那么是可以中断的,如果是0,那么是关闭中断的
x86 Family
- 询问中断控制器获得中断号n
- 保存CS,RIP,RFLAGS,SS,RSP到堆栈
- 跳转到IDT[n]指定的地址,并设置处理器状态(例如关闭中断)
RISC-V(M-Mode)
- 检查mie是否屏蔽此次中断
- 跳转 PC = (mtvec & ~0xf)
- 更新 mcasue.Interrupt = 1
中断:奠定操作系统“霸主地位”的机制
操作系统内核(代码)
- 想开就开,想关就关
应用程序
- 没有中断
- 应用程序处于保护模式下,不允许进行中断设置的更改
真正的计算机系统模型
状态
- 共享内存和每个处理器的内部状态
为什么执行死循环不会将计算机卡死?
50行实现操作系统内核
中断处理程序的秘密
参数和返回值Context
- 中断发生后,不能执行“任何代码”
- 需要把中断瞬间的处理器状态保存下来
- 中断返回时需要把寄存器恢复到处理器上
- 看看
Context里面有什么
rip指向了代码
rsp指向了程序的堆栈
内核线程和进程:进程管理 API
ThreadOS中的进程切换
x86的int寄存器是什么操作
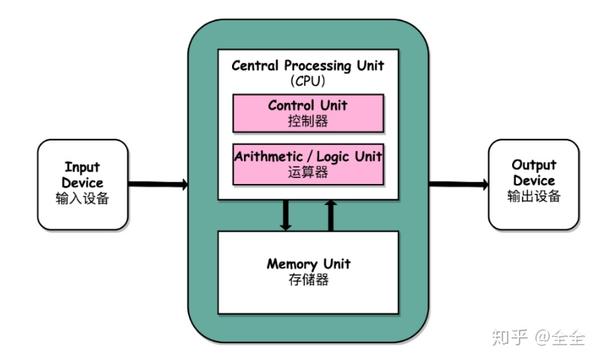
什么是操作系统
虚拟化:操作系统同时保存多个状态机
- C 程序 = 状态机
- 初始状态:
main(argc, argv) - 状态迁移:指令执行
- 包括特殊的系统调用指令 syscall
- 初始状态:
- 有一类特殊的系统调用可以管理状态机
CreateProcess(exec_file)TerminateProcess()
从线程到进程:虚拟存储系统
- 通过虚拟内存实现每次 “拿出来一个执行”
- 中断后进入操作系统代码,“换一个执行”
操作系统是状态机的管理者
操作系统在初始化加载了自己的代码之后,会起一个进程,会将这个进程的内存和寄存器加载程序执行,所有的这些事件都是由一个生成的。
创建状态机(fork)
UNIX的答案:fork
- 做一份状态机完整的复制(内存、寄存器现场)
代码解析:Fork Bomb
理解fork:习题(2)
阅读程序,写出运行结果
1 | for (int i = 0; i < 2; i++){ |
./a.out与./.a.out | cat的输出不同
办法:strace是一个办法
- 后者printf的时候,打印了Hello,但存入了缓冲区当中
创建一个shell,obs或者浏览器时候应该怎么办?
execve是重置了一个进程与状态机execute programming- 可以给这个新的程序传递一个你自己的参数
int execve(const char *pathname, char *const argv[], char *const envp[]);
执行一个
main函数,进程的strace的第一个系统调用都是一个execve任何一个程序的执行都是从
execve的系统调用开始环境变量也是从
execve这个参数传进去的,即是envp[]execv*系列的系统调用是会自动继承父进程的环境变量,默认是继承的
环境变量:PATH
pathname必须是一个文件,为path的每一个路径
1 |
|
execve是状态机的重置,那么printf这一行是不会被执行到的,原来的状态机是不复存在的
销毁状态机:(exit)
UNIX 的答案: _exit
- 立即摧毁状态机
1 | void _exit(int status) //system call |
- 销毁当前状态机,并允许有一个返回值
- 子进程终止会通知父进程 (后续课程解释)
这个简单……
- 但问题来了:多线程程序怎么办?
_exit()是直接在系统中将这个状态机抹除掉
exit_group()会将多线程所有的线程都给终止掉
exit()即c语言提供的库函数接口,则是在返回后用一个wrapper抱起来,做clean up,这样可以实现一个安全的关机
- 只会销毁仅仅一个线程
Linux世界中的应用程序(从零开始构建“最小”Linux)
如何展示一个应用程序的构建是如何完成的
Linux操作系统
Kernel
- 加载第一个进程
- 相当于在操作系统中“放置一个位于初始状态的状态机”
- Single user model(高权限)
- Kernel
- 先初始化一些对象,然后操纵这些api
- coreutils,binutils,systemd
- 为什么
systemd是进程树的根?
构造最小Linux系统
创建initramfs的目录,将系统linux的镜像拷贝进来
如果系统所有的进程都被消灭了,那么linux会报Kernel panic - not syncing: Attempted to kill init!那么内核就会拒绝工作,打印是哪个函数拒绝了工作并且打印寄存器现场。
静态连接的64位的ELF可执行文件
ELF 文件是一种二进制文件格式,全称是 Executable and Linkable Format。它是一种在类Unix系统中用于表示可执行文件、目标文件、共享库等的标准格式。ELF 文件主要用于Linux、Unix以及类Unix系统上的程序。
ELF 文件包含了程序的机器码、数据、符号表、节区信息、动态链接信息等。它的设计旨在提供一个灵活、可扩展、可移植的二进制文件格式,使得程序可以在不同的系统和架构上运行。
ELF 文件有多种类型,包括可执行文件(executable)、目标文件(object)、共享库(shared object)等。可执行文件包含了完整的可执行程序,目标文件通常是编译后的源代码,而共享库则是可供多个程序共享使用的代码库。
ELF 文件的结构相对复杂,但它的灵活性和可扩展性使得它成为了现代Unix系统中的主要二进制文件格式。
什么是busybox
BusyBox 是一个开源的、轻量级的 Unix 工具箱,旨在为嵌入式系统和小型系统提供类似于 GNU Coreutils 的基本 Unix 工具。它将许多常见的 Unix 工具(如 ls、cat、grep、find 等)整合到一个单独的可执行文件中,并且可以通过一系列的软链接来提供不同的命令名称。这使得 BusyBox 在资源受限的环境中非常有用,因为它减少了文件系统中的文件数量,同时提供了许多常用的命令和功能。
BusyBox 通常用于嵌入式 Linux 系统、小型 Linux 发行版(比如嵌入式设备、路由器、网络存储设备等),以及一些系统维护和恢复环境中。它的轻量级和灵活性使得它成为许多嵌入式系统的首选工具箱。
除了提供基本的 Unix 工具之外,BusyBox 还提供了一些额外的功能,例如用于启动和管理系统的 init 程序、用于处理软件包管理的包管理工具等。因此,BusyBox 不仅仅是一组工具的集合,还可以作为嵌入式系统的基础设施。
什么是符号链接
符号链接(Symbolic link),也称为软链接(Soft link),是操作系统中的一种特殊类型的文件。符号链接是一个指向另一个文件或目录的引用,类似于 Windows 系统中的快捷方式。它允许用户创建一个指向另一个位置的链接,使得在文件系统中一个位置的更改会同时影响到另一个位置。
符号链接与硬链接(Hard link)不同。硬链接是文件系统中的一个条目,它直接指向文件数据的存储区域,因此与原始文件有相同的 inode 号。而符号链接则是一个文件,包含了指向目标文件或目录的路径名,而不是直接引用数据。
符号链接的使用具有一些优势和特点:
- 灵活性:符号链接可以跨越文件系统边界,甚至可以跨越不同的硬盘分区。
- 安全性:创建符号链接不需要特殊的权限,因此普通用户可以创建它们。
- 可读性:符号链接保留了其目标的路径信息,因此用户可以直观地看到链接的目标。
然而,符号链接也有一些限制和注意事项:
- 如果目标文件被删除或移动,符号链接将失效,成为“悬挂链接”(dangling link)。
- 符号链接需要额外的空间来存储路径信息。
- 某些程序可能不支持符号链接,或者对其使用具有限制。
总的来说,符号链接是一种常见的文件系统特性,被广泛用于创建引用和简化文件系统结构。
busybox会根据execve系统调用传出的第一个参数的名字来找到对应的程序,可以通过一个命令来完成系统管理
initrd之后
initrd并不是我们实际看到的linux
只是一个内存里的小文件系统
- 我们 “看到” 的都是被 init 创造出来的
- 加载剩余必要的驱动程序,例如网卡
- 根据 fstab 中的信息挂载文件系统,例如网络驱动器
- 将根文件系统和控制权移交给另一个程序,例如 systemd
在 init 时多做一些事
1 | export PATH=/bin |
- pivot_root 之后才加载网卡驱动、配置 IP
- 这些都是 systemd 的工作
- (你会留意到 tty 字体变了)
- 之后 initramfs 就功成身退,资源释放
askgpt
initramfs是一个初始内存文件系统(initial RAM file system)的简称。它是一种在 Linux 启动过程中用于引导的临时文件系统,主要用于在 Linux 内核启动时提供必要的文件和工具,以便在根文件系统(root file system)挂载之前进行系统初始化和准备工作。
initramfs的主要作用包括但不限于:
- 加载关键驱动程序:在根文件系统挂载之前,
initramfs可以加载必要的驱动程序,以确保操作系统能够访问硬件设备(如磁盘驱动器、网络接口等)。- 准备根文件系统挂载:
initramfs可以包含用于挂载根文件系统所需的工具和脚本,例如mount、pivot_root等命令,以便正确地将根文件系统挂载到系统的根目录。- 修复启动问题:如果系统无法正常启动,
initramfs可以用于修复启动问题,例如修复文件系统错误、加载备用驱动程序等。
initramfs的构建过程通常涉及将一个或多个根文件系统的文件和工具打包到一个压缩的 cpio 归档文件中,并将该文件作为 Linux 内核的一部分编译进内核镜像或附加到内核镜像中。当 Linux 内核启动时,它会加载initramfs,解压缩并将其挂载为根文件系统,然后执行其中的初始化脚本和命令,最终完成系统的启动过程。总的来说,
initramfs在 Linux 启动过程中扮演了关键的角色,它为系统提供了一个临时的、功能受限的文件系统,用于在根文件系统挂载之前进行系统初始化和准备工作。
理解和入侵Linux进程地址空间
Linux进程的地址空间
- 以下程序的输出是什么
1 | printf("%p\n", main); |
1 | char *p = random(); |
pmap(1) - report memory of a process
- Claim: pmap是通过访问procfs(/proc/)实现的
- 如何验证这一点
pmap进程的内存是由连续的内存段组成的
进程的内存:例子
- 4KB r—-
- 4KB r-x–
- 16KB r—-
/proc/18090/maps这个文件其中会有进程内存有关的信息
pmap实现
claim:pmap是通过访问/proc/***/maps实现的
如何证明系统里的pmap是基于这个文件实现的?
strace可以看到其中的系统调用,其中调用了fopen来访问这个文件
strace常用来跟踪进程执行时的系统调用和所接收的信号。 在Linux世界,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。strace可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间。
选项告诉strace同时跟踪fork和vfork出来的进程,-o选项把所有strace输出写到~/straceout.txt里面,myserver是要启动和调试的程序
如果是动态连接的pmap呢?
动态链接的第一条指令是在哪里的呢?
- 静态链接的第一条指令是
execve,那么每一段内存都已经固定下来了,而动态链接的程序在运行的瞬间,甚至不知道系统里的libc是哪一个 - 地址空间当中甚至没有
libc
如果打印pc的话,那么_start()是在/lib64/ld-linux-x86-64.so上面,如果是动态链接的话,那么有一个interpreter,相当于要另外一个程序执行我现在的程序。就是这个/lib64/ld-linux-x86-64.so,在linux中,这个就相当于进程的加载器,如果程序中需要libc,那么就会将其加载到进程对应的地址空间中。
askgpt
/lib64/ld-linux-x86-64.so文件是 Linux 系统中的一个动态链接器/loader。在 Linux 中,可执行文件通常依赖于动态链接库(shared libraries),这些库通常位于系统的标准库目录中,例如/lib和/usr/lib。动态链接器负责加载这些共享库,并将它们链接到正在运行的可执行文件中,以便程序能够访问这些库中提供的功能。对于 x86-64 架构的系统,
/lib64/ld-linux-x86-64.so是动态链接器的实际二进制文件。它负责加载并运行 x86-64 架构的可执行文件,并处理这些文件所需的共享库链接。在 Linux 系统中,当您运行一个可执行文件时,操作系统会使用动态链接器来加载所需的共享库,并将它们链接到该程序中,使程序能够正确地执行所需的功能。
简而言之,
/lib64/ld-linux-x86-64.so文件是 Linux 系统中的动态链接器,它在运行时负责加载共享库并链接到正在运行的程序中。
静态链接的程序会很快执行代码,动态链接则会进行很多操作,将对应的需要的库函数搬到需要的空间中。
vvar和vdso
这两个文件是可以不进入内核的系统调用
应用程序如果需要访问操作系统内核,那么需要进行系统调用,但linux系统发现有些系统调用可以不进入内核就实现
askgpt
vvar和vdso是 Linux 进程中的两个特殊的虚拟内存区域,它们分别具有不同的作用。下面我将对它们进行详细解释:
vvar (Virtual Variables):
vvar是 Linux 内核中的一块特殊内存区域,用于存放全局变量和与进程相关的其他一些全局数据结构。这些数据通常由内核维护,用于支持一些特定的功能或提供一些系统调用。在/proc/[pid]/maps文件中,vvar区域通常会被标记为[vvar]。具体来说,
vvar内存区域包含了一些特定于进程的全局变量,比如进程 ID、线程 ID 等信息,以及一些与时间相关的数据,例如当前时间。这些信息对于某些系统调用或库函数可能是必要的。vdso (Virtual Dynamically-linked Shared Object):
vdso是另一个特殊的虚拟内存区域,也被称为 “虚拟动态链接共享对象”。它包含一些在用户空间中执行的特定功能,这些功能通常是由内核提供的,并且可以被用户空间程序直接调用,而不需要通过系统调用的方式进入内核。
vdso中的功能通常是一些高性能的系统调用,如获取当前时间、获取系统调用号等。由于这些功能在用户空间中执行,因此可以避免进入内核态的开销,从而提高性能。在/proc/[pid]/maps文件中,vdso区域通常会被标记为[vdso]。总的来说,
vvar和vdso是 Linux 内核中用于支持进程和提供高性能系统功能的两个重要的虚拟内存区域。它们提供了对进程和系统相关数据的访问,并提供了一些在用户空间执行的高性能系统调用。
进程地址空间管理
什么是mmap,munmap,mprotect
在操作系统中,
mmap、munmap和mprotect是用于管理内存映射的一组系统调用。它们通常用于创建、销毁和修改进程的虚拟内存映射。
mmap(Memory Map):
mmap系统调用用于在进程的虚拟地址空间中创建内存映射区域。通过mmap,可以将文件内容映射到内存中,也可以通过匿名映射直接映射一段虚拟内存,而无需关联到任何文件。通常,mmap被用于实现文件的内存映射、动态内存分配以及共享内存等功能。
munmap(Memory Unmap):
munmap系统调用用于从进程的虚拟地址空间中解除内存映射区域。通过munmap,可以释放先前由mmap创建的内存映射区域,将其从进程的虚拟地址空间中移除。这样可以释放内存,并且使得对应的物理页面可以被回收。
mprotect(Memory Protect):
mprotect系统调用用于修改内存映射区域的保护属性,如读取、写入和执行权限。通过mprotect,可以更改先前由mmap创建的内存映射区域的访问权限,以提高内存安全性和保护机制。例如,可以将一段内存区域标记为只读或不可执行,以防止恶意代码的注入和执行。这些系统调用通常在操作系统的内核中实现,并且由用户空间程序通过系统调用接口进行调用。它们在内存管理、文件映射和进程间通信等方面起着重要作用,是操作系统中的基本功能之一。
什么是文件描述符
Unix世界当中,everything is a file
那么什么是file descripter呢?
- 是一个指向操作系统对象的指针
askgpt
文件描述符(File Descriptor)是一个用来标识已打开文件或其他 I/O 对象的整数标识符。在 Unix 和类 Unix 操作系统中,文件描述符是进程与文件系统交互的主要方式之一。每个进程在创建时都会自动打开三个标准文件描述符,分别是:
- 标准输入(stdin):文件描述符为 0,用于从进程中读取输入数据。
- 标准输出(stdout):文件描述符为 1,用于向进程中写入输出数据。
- 标准错误(stderr):文件描述符为 2,用于向进程中写入错误消息。
除了这三个标准文件描述符之外,进程还可以通过打开文件、管道、套接字等操作系统资源来获取额外的文件描述符。每次打开一个文件或者进行 I/O 操作,操作系统都会分配一个新的文件描述符给该操作,用于标识这个特定的文件或 I/O 对象。
文件描述符通常是一个非负整数。在大多数情况下,文件描述符从 0 开始递增,但是具体的实现可能会有所不同。例如,Windows 操作系统使用的是句柄(handle)而不是文件描述符。
文件描述符在 Unix 和类 Unix 操作系统中的重要性体现在它们是进行 I/O 操作的主要标识符,允许进程与文件系统、网络等交互。开发人员通常使用文件描述符来打开、读取、写入、关闭文件以及进行进程间通信。
磁盘结尾55aa代表什么
在计算机领域,特定字节序列 0x55AA 在主引导记录(Master Boot Record,MBR)的末尾是一种约定,表示磁盘的有效引导扇区。MBR 是一种位于磁盘第一个扇区(通常是第0号扇区)的特殊区域,用于存储引导加载程序和分区表等重要信息。
具体来说,0x55AA 是 MBR 的两个字节中的最后两个字节,也被称为 MBR 的 “magic number”。当操作系统加载 MBR 时,会检查这两个字节是否等于 0x55AA。如果是,它将认为该磁盘是一个有效的引导磁盘,并尝试加载其中的引导加载程序。
这种约定的设计目的是确保磁盘引导扇区的有效性和可靠性。如果这两个字节不等于 0x55AA,操作系统通常会认为该磁盘没有引导加载程序或者引导加载程序损坏,因此会拒绝启动该磁盘。
总之,磁盘末尾的 0x55AA 字节序列表示 MBR 的有效性标志,指示操作系统该磁盘可以用作引导设备。
入侵地址空间
物理外挂:金山游侠
在进程的内存中找到代表“金钱”、“生命”的中药书信并且改掉
包含非常贴心的“游戏内呼叫”功能
通过扫描内存,确定内存的地址并且将其修改为我想要的值
WriteProcessMemory和ReadProcessMemory
驱动外挂:按键精灵
编写新的驱动,实现更加简单
给进程发送键盘和鼠标的事件
时间外挂:变速齿轮
进程就是状态机,状态机除了系统调用以外所有的指令都是计算
- 除了syscall,是不能感知时间的
- 只要“劫持”和时间相关的syscall,就能改变程序对时间的认识
- 原则上程序仍然可以用间接信息“感知”的
操作系统实验生存指南
程序 = 计算机系统 = 状态机
- 调试器的本质是 “检查状态”
- 我们能不能用自己想要的方式去检查状态?
- 例如,像 model checker 那样把一个链表绘制出来?
- AskGPT: How to use Python to parse and check/visualize C/C++ program state in GDB?
- GPT-4 甚至给出了正确的文档 URL
然后我们就可以做任何事了
- TUI Window API
- 甚至,我们可以做另一个 debugging front-end
系统调用和UNIX Shell
UNIX Shell
Shell是一门“把用户指令翻译成系统调用”的编程语言
Unix Shell 是 Unix 操作系统中的一个关键组件,它是用户与操作系统内核进行交互的主要界面。Shell 提供了一个命令行界面(Command-Line Interface,CLI),允许用户输入命令并执行各种操作。
Unix Shell 的主要功能包括:
- 命令解释和执行:用户可以在 Shell 中输入命令,并通过 Shell 解释和执行这些命令。Shell 提供了一系列内置命令和系统命令,以及能够调用系统程序和应用程序的功能。
- 脚本编程:Shell 允许用户编写脚本文件,其中包含一系列 Shell 命令和控制结构,以实现复杂的任务和自动化操作。这种脚本编程方式称为 Shell 脚本编程,是 Unix 系统中常见的一种脚本编程方式。
- 文件操作:Shell 提供了丰富的文件操作命令和功能,允许用户对文件和目录进行创建、删除、复制、移动、重命名等操作,以及查看文件内容、权限和属性等信息。
- 进程控制:Shell 允许用户管理系统中运行的进程,包括启动新进程、挂起或终止现有进程,以及监视和管理进程的状态和资源使用情况。
- 环境配置:Shell 允许用户配置和管理当前的工作环境,包括设置环境变量、修改路径、定义别名等,以满足个性化和特定需求。
Unix 操作系统中有多种 Shell 的实现,其中最常见的是 Bourne Shell(sh)、Bourne Again Shell(bash)、C Shell(csh)、Korn Shell(ksh)等。每种 Shell 都有自己的特点和语法,但它们通常都遵循 Unix Shell 的基本原则和功能。Unix Shell 在 Unix 和类 Unix 系统中广泛应用,在服务器管理、系统编程、软件开发等领域都具有重要作用。
Shell语言
- 先做字符串级的预编译,替换字符串
- 把shell代码解析成一棵树
- 翻译为系统调用的序列
The Shell Programming Language
基于文本替换的快速工作流搭建
- 重定向:
cmd > file < file 2> /dev/null - 顺序结构:
cmd1; cmd2,cmd1 && cmd2,cmd1 || cmd2 - 管道:
cmd1 | cmd2 - 预处理:
$(),<() - 变量/环境变量、控制流……
Job control
- 类比窗口管理器里的 “叉”、“最小化”
- jobs, fg, bg, wait
- (今天的 GUI 并没有比 CLI 多做太多事)
strace ./a.out & | vim -利用vim直接编辑strace的结果
1 | set follow-fork-mode child |
ls管道给wc在操作系统上是怎么实现的?
pipe会创建两个文件描述符,一个指向读口,一个指向写口,最后得到图片
为什么sudo echo hello > /etc/a.txt会Permission denied?
- 因为重定向会在
execve的sudo之前就会先去准备好文件描述符,而此时用户是没有root权限的
C标准库和实现
libc与操作系统
libc是对文件描述符进行了封装
popen和pclose
popen是一个标准 C 库函数,用于创建一个管道,并启动一个子进程来执行一个命令,并且可以通过管道进行输入和输出的交互。popen函数与system函数类似,但允许您通过管道与子进程进行双向通信。具体来说,
popen函数会创建一个管道,并使用fork函数创建一个子进程。在子进程中,它调用exec系列函数执行指定的命令。而在父进程中,popen函数返回一个指向 FILE 结构体的指针,通过这个指针,您可以对子进程的输入和输出进行读写操作。
popen函数的原型如下:
2
FILE *popen(const char *command, const char *mode);其中,
command参数是要执行的命令,mode参数指定了打开管道的模式,可以是"r"(只读模式)或"w"(只写模式)。
popen函数的返回值是一个指向FILE结构体的指针,可以通过这个指针进行输入和输出操作。一般情况下,您可以使用标准 I/O 函数(如fread、fwrite、fprintf、fscanf等)来读取或写入数据到子进程的标准输入或标准输出。当不再需要与子进程通信时,可以使用
pclose函数关闭与子进程的连接,并等待子进程的退出。pclose函数会返回子进程的退出状态码。总之,
popen函数允许您启动一个子进程来执行一个命令,并通过管道与子进程进行双向通信,这在编写需要执行外部命令的程序时非常有用。
pclose是一个标准 C 库函数,用于关闭通过popen函数创建的子进程,并等待子进程的退出。它的作用类似于fclose函数,但是它不仅关闭了文件流,还会等待关联的子进程退出。具体来说,
pclose函数会等待与指定文件流相关联的子进程退出,并且返回子进程的终止状态。如果成功关闭了子进程,pclose函数返回子进程的退出状态码;如果关闭失败,或者文件流没有与任何子进程关联,或者发生了其他错误,则返回 -1。
pclose函数的原型如下:
2
int pclose(FILE *stream);其中,
stream参数是通过popen函数返回的文件流指针。使用
pclose函数时,通常需要注意以下几点:
- 如果成功关闭了子进程,
pclose函数会返回子进程的退出状态码,可以通过WIFEXITED宏和WEXITSTATUS宏获取退出状态。- 如果
pclose函数返回 -1,表示关闭失败或者发生了其他错误,可以通过errno全局变量获取具体的错误信息。- 在调用
pclose函数之前,务必使用fclose函数关闭与文件流相关的标准 I/O 流。总之,
pclose函数是用于关闭通过popen函数创建的子进程,并等待子进程退出的函数,非常适用于需要与外部命令进行交互的情况。
环境变量
environment应该不是操作系统赋值的
具体的环境变量
操作系统在execve的时候会在内存中放上argc、argv、envp
初始状态里面有什么?
如何分配一大段内存?
- 用
MAP_ANONYMOUS申请,想多少有多少- 超过物理内存上限都行
- 反而,操作系统不支持分配一小段内存
MAP_ANONYMOUS是一个常量,通常用于在 Unix/Linux 操作系统中的内存映射(memory mapping)操作中。它指示内核在内存中创建一个匿名映射区域,而不是将映射与文件关联起来。在使用
mmap()系统调用创建内存映射时,如果您将MAP_ANONYMOUS作为标志传递给mmap(),则内核将为您分配一块匿名的内存区域,而不是映射到任何文件。这意味着您可以使用内存映射来创建一个不依赖于文件系统的内存区域,这在一些特定的应用场景中很有用。通常情况下,
MAP_ANONYMOUS会与MAP_PRIVATE或MAP_SHARED一起使用,以指示内存区域是私有的(只能被创建它的进程访问)还是共享的(可以被其他进程访问)。总之,
MAP_ANONYMOUS是一个标志,用于告诉内核创建一个不关联任何文件的内存映射区域,通常与mmap()系统调用一起使用。
malloc, Fast and Slow
设置两套系统:
- Fast path
- 性能极好、并行度极高、覆盖大部分情况
- 但有小概率会失败 (fall back to slow path)
- Slow path
- 不在乎那么快
- 但把困难的事情做好
- 计算机系统里有很多这样的例子 (比如 cache)
人类也是这样的系统
- Daniel Kahneman. Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011.
可执行文件和加载
内核和应用程序之间有一个系统调用
什么是可执行文件?
- 是一个操作系统中的对象(文件)
- 一个字节序列,我们可以用文本编辑
作为“数据结构“的可执行文件
ELF Loader
Boot Block Loader
加载操作系统内核
- 也是一个ELF文件
- 解析数据结构 + 复制到内存 + 跳转
linux内核存在ELF的加载器
最小动态链接和加载器
当需要发布补丁的时候
- 如果程序是静态链接的,那么一千个程序都需要重新编译
- 所以linux中绝大部分应用都是动态链接的
系统只有一份libc
- Library保持接口的向后兼容
- 补丁发布后不再需要重编译所有依赖的应用
- Semantic Versioning
- “Compatible”是个微妙的定义
动态链接
- 如果编译器、连接器、加载器都受你控制
- 怎么设计、实现一个“最直观”的动态链接格式?
- 再去考虑怎么改进它
- 假设编译器可以为你生成位置无关代码(PIC)
1 | #include "dl.h" |
动态链接库是直接映射到内存当中的
askgpt
动态链接是一种在程序运行时将代码和数据库文件加载到内存中,并进行链接的机制。它允许程序在运行时使用外部库中的函数和符号,从而实现代码的共享和重用。以下是动态链接的实现原理:
- 编译目标文件: 首先,源代码通过编译器编译成目标文件(通常是 ELF 格式的文件)。编译过程会生成用于描述代码和数据的符号表以及重定位表。
- 链接共享库: 如果程序引用了外部的共享库(动态链接库),则在链接阶段会记录对共享库的依赖关系。编译器会将共享库的名称和所需符号信息嵌入到可执行文件中,但不会将实际的代码和数据复制到可执行文件中。
- 程序加载: 当程序被加载到内存中时,操作系统会解析可执行文件中的共享库依赖关系,并查找并加载相应的共享库文件。如果需要,还会解析和加载共享库的依赖库,直到所有依赖关系都被满足。
- 符号解析: 加载共享库后,操作系统会将程序中对外部函数和符号的引用解析为实际的内存地址。这通常通过符号表进行,操作系统根据符号名称查找对应的地址,并更新程序中的引用。
- 重定位: 如果共享库中的代码和数据被加载到不同的地址,或者共享库引用了其他共享库,可能会发生地址偏移,需要进行重定位。操作系统会根据重定位表中的信息,将引用的地址更新为正确的地址。
- 执行程序: 一旦所有符号解析和重定位都完成,程序就可以正常执行了。在运行时,程序可以动态地调用共享库中的函数,并且共享库的代码和数据只会在第一次使用时加载到内存中。
总的来说,动态链接通过在程序运行时加载共享库,解析符号引用,并进行重定位,实现了程序和外部库的链接。这种机制允许程序在运行时共享代码和数据,提高了代码的复用性和灵活性。
可执行文件和加载(ELF动态链接和加载)
动态链接与加载原理
1 | extern void foo(); |
编译器遇到函数调用,应该翻译成哪种指令?
- 如果 foo 来自同一个动态链接库
call foo
- 如果 foo 来自另一个动态链接库
call TABLE(foo)
我们发明了 PLT (Procedure Linkage Table)
- 函数实在太多了
- 每个都标记区分,太难看了
- 编译器总是生成一个直接的 call
- 来自另一个动态链接库:call putcahr@PLT
🌶️ELF动态链接和加载
初始状态是指向了/lib64/linux-ld.so的__start()指令
一个有趣(且根本)的问题
- 库函数调用看起来“很浪费”
- 连续的跳转
- 为什么不在加载时执行静态连接
LD_PRELOAD
除非是在编译的时候使用了runtime
LD_PRELOAD是一个用于设置动态链接器的环境变量,它指定了在程序运行时优先加载的共享库。具体来说,它会在程序加载其他共享库之前,将指定的共享库加载到内存中。这样可以使得指定的共享库中的函数或符号优先于系统默认的库被调用。
LD_PRELOAD的作用主要有以下几点:
- 劫持系统调用:可以通过
LD_PRELOAD机制来劫持系统调用,从而在程序运行时替换系统调用的行为。例如,可以使用LD_PRELOAD来替换标准库中的malloc和free函数,以实现自定义的内存分配和管理策略。- 修改程序行为:通过加载指定的共享库,可以修改程序的行为或添加额外的功能。例如,可以使用
LD_PRELOAD来修改程序的输入输出行为,实现输入输出的记录、过滤或重定向。- 调试和性能分析:
LD_PRELOAD还可以用于调试和性能分析。通过加载自定义的共享库,可以在程序运行时收集性能数据或添加调试信息,以便分析程序的行为和性能瓶颈。需要注意的是,使用
LD_PRELOAD机制可能会对程序的稳定性和可移植性产生影响,因此在使用时需要谨慎考虑。
操作系统进程的实现
进程的地址空间
CR3寄存器
AbstractMachine对地址空间的抽象
CR3 寄存器是 x86 架构中的一种控制寄存器,称为页目录基址寄存器(Page Directory Base Register)。CR3 寄存器存储了页目录表的物理地址,页目录表是用于虚拟地址到物理地址转换的关键数据结构之一。它的作用主要与虚拟内存管理相关。
CR3 寄存器的主要作用如下:
- 页表基址设置:CR3 寄存器存储了页目录表的物理地址,通过这个地址,处理器能够找到页目录表的起始位置。页目录表包含了虚拟地址到物理地址的映射信息,它指导操作系统如何将虚拟地址转换为物理地址。
- 页表切换:当操作系统进行进程切换时,需要切换页表以更改虚拟地址空间的映射关系。通过修改 CR3 寄存器的值,操作系统可以将当前进程的页表切换为下一个进程的页表,从而实现不同进程间的内存隔离。
- 页表缓存刷新:在更新页表时,处理器内部的 TLB(Translation Lookaside Buffer,转换后备缓冲器)可能会包含过时的地址映射信息。更新 CR3 寄存器可以触发 TLB 刷新,确保处理器使用最新的页表信息进行地址转换,避免出现地址映射错误。
总之,CR3 寄存器是虚拟内存管理的关键组成部分之一,它存储了页目录表的物理地址,通过控制 CR3 寄存器的值,操作系统能够管理和切换进程的虚拟地址空间,实现进程间的内存隔离和地址转换。
为什么能做到这些?
- 存储页表地址:CR3 寄存器存储了当前进程的页表(页目录表)的物理地址。通过修改 CR3 寄存器的值,操作系统可以切换不同进程的页表。每个进程都有自己的页表,用于将其虚拟地址转换为物理地址。因此,通过修改 CR3 寄存器,操作系统可以切换进程间的地址映射关系,实现进程间的内存隔离。
- TLB 刷新:当修改 CR3 寄存器时,处理器会自动刷新 TLB(Translation Lookaside Buffer,转换后备缓冲器)。TLB 是一个硬件缓存,用于存储最近的虚拟地址到物理地址的映射关系。当操作系统切换进程时,当前进程的页表被修改,原先在 TLB 中的虚拟地址映射就可能变得无效。通过刷新 TLB,处理器会清除现有的缓存,确保下次访问时使用最新的页表信息进行地址转换。
- 内存隔离:不同进程拥有各自的虚拟地址空间,每个进程的页表都只包含了其自身的虚拟地址到物理地址的映射关系。通过在进程切换时修改 CR3 寄存器,操作系统可以确保每个进程只能访问到属于自己的内存区域,从而实现进程间的内存隔离。这种机制防止了进程之间的相互干扰和非法访问。
地址翻译
- 所有的虚拟内存地址都翻译为物理内存地址
处理器当中既有指令缓存又有数据缓存
- 对于TLB来说,既有ITLB又有DTLB
ITLB 和 DTLB 是计算机体系结构中的两个重要组成部分,用于处理指令和数据的地址转换。
- ITLB(指令转换查找缓冲器):
- ITLB 是一个硬件缓存,用于存储指令地址到物理地址的转换信息。
- 当 CPU 执行程序时,它需要将程序的指令地址转换为实际的物理地址,以便访问内存中的指令。ITLB 负责存储最近使用的指令地址的转换结果,以加速后续的指令访问。
- ITLB 的大小和工作方式因处理器架构而异,但其目标是减少指令访问所需的地址转换时间,从而提高执行效率。
- DTLB(数据转换查找缓冲器):
- DTLB 类似于 ITLB,但它用于存储数据访问的地址转换信息。
- 当程序执行中涉及到数据访问时,CPU 需要将逻辑地址转换为物理地址,以便在内存中读取或写入数据。DTLB 存储最近使用的数据地址的转换结果,以提高后续数据访问的速度。
- 与 ITLB 类似,DTLB 的大小和工作方式因处理器架构而异,但其目的都是减少数据访问所需的地址转换时间,从而提高系统的整体性能。
这两个缓冲器对于提高 CPU 效率和性能至关重要,因为它们减少了执行指令和访问数据时必须进行的地址转换次数,从而减少了内存访问的延迟。
虚假的地址空间
我们可以将两个进程的不同虚拟地址分配在相同的物理空间上
libc的代码应该只有一个副本- 如何证明这一点?
如果执行一千次填充数据的程序的话,成熟的操作系统应该不会卡死
写时复制(copy on write)
写实复制技术的核心思想是只在必要的时候复制数据,而不是立即复制整个共享的内存页。因此,当父进程或子进程尝试修改共享内存页中的数据时,操作系统只会复制需要修改的内容,而不是整个内存页。
具体过程如下:
- 共享内存页: 父进程和子进程在创建时共享相同的内存页,这包括代码、数据和堆栈等。
- 写操作发生: 如果父进程或子进程尝试修改共享内存页中的某些数据,这时写实复制机制生效。
- 新页创建: 操作系统会为试图进行写操作的进程创建一个新的内存页,这个新页是原共享内存页的副本。
- 复制需要修改的内容: 只有需要修改的部分数据会被复制到新的内存页中。其他未被修改的数据仍然共享。
- 进程写入: 进程被允许在新的内存页中进行写操作。此时,父进程和子进程的内存空间就分离了,它们各自拥有独立的内存页。
这样的设计有效地延迟了内存页的复制,只有在发生写操作时才进行必要的复制,避免了不必要的资源浪费。这种延迟复制的机制使得创建子进程的代价较低,因为初始时父进程和子进程共享同一内存页,只有在需要修改的时候才进行复制。
如何在这个新的内存页当中确定哪些是被修改过的哪些是没被修改过的呢
在写实复制的实现中,操作系统使用了一种页表的技术来标记内存页中的哪些部分是被修改过的,以便在需要的时候进行复制。这种技术的基本原理是使用页表中的标志位来追踪每一页的修改状态。以下是一般的步骤:
- 页表项标志位: 操作系统的页表中通常会包含一些标志位,其中之一是”写入”(Write)标志位。当一个进程尝试写入一个内存页时,CPU 会检查与该内存页相关的页表项的”写入”标志位。
- 写入操作触发: 当一个进程试图对共享的内存页进行写入操作时,如果该内存页的”写入”标志位被置为“未写入”状态,操作系统就会触发写实复制机制。
- 新页的创建和复制: 操作系统为这个进程创建一个新的内存页,并将需要被修改的数据复制到新页中。同时,操作系统会更新页表,将原内存页标记为“只读”(Read-Only),并将新页标记为“可写”(Writeable)。
- 写操作完成: 进程现在将写入数据的操作应用于新页,而原内存页变为只读状态。其他进程仍然共享原内存页,不会受到写入操作的影响。
- 后续写入操作: 对于新页的后续写入操作,将直接影响新页,而不会再触发写实复制机制。
通过这种方式,操作系统能够跟踪哪些部分是被修改过的,只有在真正需要时才进行复制。这有效地降低了写实复制的开销,提高了效率。这种技术也称为“写时复制”(Copy-on-Write)。
fork创建的是状态机的快照
写时复制创建的是内存的快照
快照
用来进行版本管理和系统容错、回滚
系统初始化的快照
处理器调度问题
Tmux操作快捷键
会话快捷键
Ctrl+b d:分离当前会话。Ctrl+b s:列出所有会话。Ctrl+b $:重命名当前会话。
窗格快捷键
Ctrl+b %:划分左右两个窗格。Ctrl+b ":划分上下两个窗格。Ctrl+b <arrow key>:光标切换到其他窗格。<arrow key>是指向要切换到的窗格的方向键,比如切换到下方窗格,就按方向键↓。Ctrl+b ;:光标切换到上一个窗格。Ctrl+b o:光标切换到下一个窗格。Ctrl+b {:当前窗格与上一个窗格交换位置。Ctrl+b }:当前窗格与下一个窗格交换位置。Ctrl+b Ctrl+o:所有窗格向前移动一个位置,第一个窗格变成最后一个窗格。Ctrl+b Alt+o:所有窗格向后移动一个位置,最后一个窗格变成第一个窗格。Ctrl+b x:关闭当前窗格。Ctrl+b !:将当前窗格拆分为一个独立窗口。Ctrl+b z:当前窗格全屏显示,再使用一次会变回原来大小。Ctrl+b Ctrl+<arrow key>:按箭头方向调整窗格大小。Ctrl+b q:显示窗格编号。
窗口快捷键
Ctrl+b c:创建一个新窗口,状态栏会显示多个窗口的信息。Ctrl+b p:切换到上一个窗口(按照状态栏上的顺序)。Ctrl+b n:切换到下一个窗口。Ctrl+b <number>:切换到指定编号的窗口,其中的<number>是状态栏上的窗口编号。Ctrl+b w:从列表中选择窗口。Ctrl+b ,:窗口重命名。
其他命令
1 | # 列出所有快捷键,及其对应的 Tmux 命令 |